本文共 18109 字,大约阅读时间需要 60 分钟。
参考:
参考:
参考:
参考:
python下载文件的三种方法
当然你也可以利用ftplib从ftp站点下载文件。此外Python还提供了另外一种方法requests。
下面来看看三种方法是如何来下载zip文件的:
方法一:
import urllib import urllib2 import requestsprint "downloading with urllib" url = 'http://www.pythontab.com/test/demo.zip' print "downloading with urllib"urllib.urlretrieve(url, "demo.zip")
1.urlopen()方法 urllib.urlopen(url[, data[, proxies]]) :创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据。 参数url表示远程数据的路径,一般是网址; 参数data表示以post方式提交到url的数据(玩过web的人应该知道提交数据的两种方式:post与get。如果你不清楚,也不必太在意,一般情况下很少用到这个参数); 参数proxies用于设置代理。 urlopen返回 一个类文件对象,它提供了如下方法: read() , readline() , readlines() , fileno() , close() :这些方法的使用方式与文件对象完全一样; info():返回一个httplib.HTTPMessage 对象,表示远程服务器返回的头信息 getcode():返回Http状态码。如果是http请求,200表示请求成功完成;404表示网址未找到; geturl():返回请求的url;
import urlliburl = "http://www.baidu.com/"#urlopen()sock = urllib.urlopen(url)htmlCode = sock.read()sock.closefp = open("e:/1.html","wb")fp.write(htmlCode)fp.close#urlretrieve()urllib.urlretrieve(url, 'e:/2.html') urllib模块urlretrieve方法
下面我们再来看看 urllib 模块提供的 urlretrieve() 函数。urlretrieve() 方法直接将远程数据下载到本地。
>>> help(urllib.urlretrieve)Help on function urlretrieve in module urllib:urlretrieve(url, filename=None, reporthook=None, data=None)
urllib.urlretrieve(url[, filename[, reporthook[, data]]])
参数说明: url:外部或者本地url filename:指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据); reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。我们可以利用这个回调函数来显示当前的下载进度。 data:指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。import urllibdef callbackfunc(blocknum, blocksize, totalsize): '''回调函数 @blocknum: 已经下载的数据块 @blocksize: 数据块的大小 @totalsize: 远程文件的大小 ''' percent = 100.0 * blocknum * blocksize / totalsize if percent > 100: percent = 100 print "%.2f%%"% percenturl = 'http://www.sina.com.cn'local = 'd:\\sina.html'urllib.urlretrieve(url, local, callbackfunc)
#爬取百度贴吧一些小图片 #urllib.urlretriev---将远程数据下载到本地 import urllib import urllib2 import re #http://tieba.baidu.com/p/3868127254 a = raw_input('inpt url:') s = urllib2.urlopen(a) s1 = s.read() def getimg(aaa): reg = re.compile(r'img.src="(.*?)"') #reg = re.compile(r'') l = re.findall(reg, aaa) tmp =0 for x in l: tmp += 1 urllib.urlretrieve(x, '%s.jpg' % tmp) #print s1 getimg(s1) 方法二:
import urllib2print "downloading with urllib2"url = 'http://www.pythontab.com/test/demo.zip' f = urllib2.urlopen(url) data = f.read() with open("demo2.zip", "wb") as code: code.write(data) 方法三:
import requests print "downloading with requests"url = 'http://www.pythontab.com/test/demo.zip' r = requests.get(url) with open("demo3.zip", "wb") as code: code.write(r.content)看起来使用urllib最为简单,一句语句即可。当然你可以把urllib2缩写成: f = urllib2.urlopen(url) with open("demo2.zip", "wb") as code: code.write(f.read()) 使用requests模块显示下载进度
1. 相关资料
请求关键参数:stream=True。默认情况下,当你进行网络请求后,响应体会立即被下载。你可以通过 stream 参数覆盖这个行为,推迟下载响应体直到访问 Response.content 属性。
tarball_url = 'https://github.com/kennethreitz/requests/tarball/master'r = requests.get(tarball_url, stream=True)此时仅有响应头被下载下来了,连接保持打开状态,因此允许我们根据条件获取内容:
if int(r.headers['content-length']) < TOO_LONG: content = r.content ...进一步使用 Response.iter_content 和 Response.iter_lines 方法来控制工作流,或者以 Response.raw 从底层urllib3的 urllib3.HTTPResponse
from contextlib import closingwith closing(requests.get('http://httpbin.org/get', stream=True)) as r: # Do things with the response here. 保持活动状态(持久连接)
归功于urllib3,同一会话内的持久连接是完全自动处理的,同一会话内发出的任何请求都会自动复用恰当的连接!注意:只有当响应体的所有数据被读取完毕时,连接才会被释放到连接池;所以确保将 stream 设置为 False 或读取 Response 对象的 content 属性。
2. 下载文件并显示进度条
with closing(requests.get(self.url(), stream=True)) as response: chunk_size = 1024 # 单次请求最大值 content_size = int(response.headers['content-length']) # 内容体总大小 progress = ProgressBar(self.file_name(), total=content_size, unit="KB", chunk_size=chunk_size, run_status="正在下载", fin_status="下载完成") with open(file_name, "wb") as file: for data in response.iter_content(chunk_size=chunk_size): file.write(data) progress.refresh(count=len(data))
进度条类的实现
在Python3中,print()方法的默认结束符(end=’\n’),当调用完之后,光标自动切换到下一行,此时就不能更新原有输出。
将结束符改为“\r”,输出完成之后,光标会回到行首,并不换行。此时再次调用print()方法,就会更新这一行输出了。
结束符也可以使用“\d”,为退格符,光标回退一格,可以使用多个,按需求回退。
在结束这一行输出时,将结束符改回“\n”或者不指定使用默认
下面是一个格式化的进度条显示模块。代码如下:
#!/usr/bin/env python3import requestsfrom contextlib import closing"""作者:微微寒链接:https://www.zhihu.com/question/41132103/answer/93438156来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。"""class ProgressBar(object): def __init__(self, title, count=0.0, run_status=None, fin_status=None, total=100.0, unit='', sep='/', chunk_size=1.0): super(ProgressBar, self).__init__() self.info = "[%s] %s %.2f %s %s %.2f %s" self.title = title self.total = total self.count = count self.chunk_size = chunk_size self.status = run_status or "" self.fin_status = fin_status or " " * len(self.statue) self.unit = unit self.seq = sep def __get_info(self): # 【名称】状态 进度 单位 分割线 总数 单位 _info = self.info % (self.title, self.status, self.count/self.chunk_size, self.unit, self.seq, self.total/self.chunk_size, self.unit) return _info def refresh(self, count=1, status=None): self.count += count # if status is not None: self.status = status or self.status end_str = "\r" if self.count >= self.total: end_str = '\n' self.status = status or self.fin_status print(self.__get_info(), end=end_str)def main(): with closing(requests.get("http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3", stream=True)) as response: chunk_size = 1024 content_size = int(response.headers['content-length']) progress = ProgressBar("razorback", total=content_size, unit="KB", chunk_size=chunk_size, run_status="正在下载", fin_status="下载完成") # chunk_size = chunk_size < content_size and chunk_size or content_size with open('./file.mp3', "wb") as file: for data in response.iter_content(chunk_size=chunk_size): file.write(data) progress.refresh(count=len(data))if __name__ == '__main__': main() python编写断点续传下载软件
另一种方法是调用 curl 之类支持断点续传的下载工具。后续补充
一、HTTP断点续传原理 其实HTTP断点续传原理比较简单,在HTTP数据包中,可以增加Range头,这个头以字节为单位指定请求的范围,来下载范围内的字节流。如: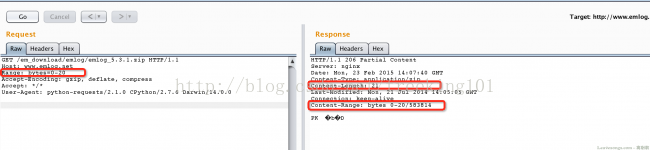
如上图勾下来的地方,我们发送数据包时选定请求的内容的范围,返回包即获得相应长度的内容。所以,我们在下载的时候,可以将目标文件分成很多“小块”,每次下载一小块(用Range标明小块的范围),直到把所有小块下载完。
当网络中断,或出错导致下载终止时,我们只需要记录下已经下载了哪些“小块”,还没有下载哪些。下次下载的时候在Range处填写未下载的小块的范围即可,这样就能构成一个断点续传。
其实像迅雷这种多线程下载器也是同样的原理。将目标文件分成一些小块,再分配给不同线程去下载,最后整合再检查完整性即可。
二、Python下载文件实现方式
我们仍然使用之前介绍过的requests库作为HTTP请求库。
先看看这段文档:,当请求时设置steam=True的时候就不会立即关闭连接,而我们以流的形式读取body,直到所有信息读取完全或者调用Response.close关闭连接。
所以,如果要下载大文件的话,就将steam设置为True,慢慢下载,而不是等整个文件下载完才返回。
stackoverflow上有同学给出了一个简单的下载demo:
def download_file(url): local_filename = url.split('/')[-1] # NOTE the stream=True parameter r = requests.get(url, stream=True) with open(local_filename, 'wb') as f: for chunk in r.iter_content(chunk_size=1024): if chunk: # filter out keep-alive new chunks f.write(chunk) f.flush() return local_filename这基本上就是我们核心的下载代码了。 当使用requests的get下载大文件/数据时,建议使用使用stream模式。
当把get函数的stream参数设置成False时,它会立即开始下载文件并放到内存中,如果文件过大,有可能导致内存不足。
当把get函数的stream参数设置成True时,它不会立即开始下载,当你使用iter_content或iter_lines遍历内容或访问内容属性时才开始下载。需要注意一点:文件没有下载之前,它也需要保持连接。
iter_content:一块一块的遍历要下载的内容 iter_lines:一行一行的遍历要下载的内容 使用上面两个函数下载大文件可以防止占用过多的内存,因为每次只下载小部分数据。示例代码:r = requests.get(url_file, stream=True)f = open("file_path", "wb")for chunk in r.iter_content(chunk_size=512):if chunk:f.write(chunk) 三、断点续传结合大文件下载
好,我们结合这两个知识点写个小程序:支持断点续传的下载器。
我们可以先考虑一下需要注意的有哪些点,或者可以添加的功能有哪些:
1. 用户自定义性:可以定义cookie、referer、user-agent。如某些下载站检查用户登录才允许下载等情况。2. 很多服务端不支持断点续传,如何判断?3. 怎么去表达进度条?4. 如何得知文件的总大小?使用HEAD请求?那么服务器不支持HEAD请求怎么办?5. 下载后的文件名怎么处理?还要考虑windows不允许哪些字符做文件名。 (header中可能有filename,url中也有filename,用户还可以自己指定filename)6. 如何去分块,是否加入多线程。
其实想一下还是有很多疑虑,而且有些地方可能一时还解决不了。先大概想一下各个问题的答案:
1. headers可以由用户自定义2. 正式下载之前先HEAD请求,得到服务器status code是否是206,header中是否有Range-content等标志,判断是否支持断点续传。3. 可以先不使用进度条,只显示当前下载大小和总大小4. 在HEAD请求中匹配出Range-content中的文件总大小,或获得content-length大小(当不支持断点续传的时候会返回总content-length)。如果不支持HEAD请求或没有content-type就设置总大小为0.(总之不会妨碍下载即可)5. 文件名优先级:用户自定义 > header中content-disposition > url中的定义,为了避免麻烦,我这里和linux下的wget一样,忽略content-disposition的定义。如果用户不指定保存的用户名的话,就以url中最后一个“/”后的内容作为用户名。6. 为了稳定和简单,不做多线程了。如果不做多线程的话,我们分块就可以按照很小来分,如1KB,然后从头开始下载,一K一K这样往后填充。这样避免了很多麻烦。当下载中断的时候,我们只需要简单查看当前已经下载了多少字节,就可以从这个字节后一个开始继续下载。解决了这些疑问,我们就开始动笔了。实际上,疑问并不是在未动笔的时候干想出来的,基本都是我写了一半突然发现的问题。
解决了这些疑问,我们就开始动笔了。实际上,疑问并不是在未动笔的时候干想出来的,基本都是我写了一半突然发现的问题。
def download(self, url, filename, headers = {}): finished = False block = self.config['block'] local_filename = self.remove_nonchars(filename) tmp_filename = local_filename + '.downtmp' if self.support_continue(url): # 支持断点续传 try: with open(tmp_filename, 'rb') as fin: self.size = int(fin.read()) + 1 except: self.touch(tmp_filename) finally: headers['Range'] = "bytes=%d-" % (self.size, ) else: self.touch(tmp_filename) self.touch(local_filename) size = self.size total = self.total r = requests.get(url, stream = True, verify = False, headers = headers) if total > 0: print "[+] Size: %dKB" % (total / 1024) else: print "[+] Size: None" start_t = time.time() with open(local_filename, 'ab') as f: try: for chunk in r.iter_content(chunk_size = block): if chunk: f.write(chunk) size += len(chunk) f.flush() sys.stdout.write('\b' * 64 + 'Now: %d, Total: %s' % (size, total)) sys.stdout.flush() finished = True os.remove(tmp_filename) spend = int(time.time() - start_t) speed = int(size / 1024 / spend) sys.stdout.write('\nDownload Finished!\nTotal Time: %ss, Download Speed: %sk/s\n' % (spend, speed)) sys.stdout.flush() except: import traceback print traceback.print_exc() print "\nDownload pause.\n" finally: if not finished: with open(tmp_filename, 'wb') as ftmp: ftmp.write(str(size)) 这是下载的方法。首先if语句调用self.support_continue(url)判断是否支持断点续传。如果支持则从一个临时文件中读取当前已经下载了多少字节,如果不存在这个文件则会抛出错误,那么size默认=0,说明一个字节都没有下载。
然后就请求url,获得下载连接,for循环下载。这个时候我们得抓住异常,一旦出现异常,不能让程序退出,而是正常将当前已下载字节size写入临时文件中。下次再次下载的时候读取这个文件,将Range设置成bytes=(size+1)-,也就是从当前字节的后一个字节开始到结束的范围。从这个范围开始下载,来实现一个断点续传。
判断是否支持断点续传的方法还兼顾了一个获得目标文件大小的功能:
def support_continue(self, url): headers = { 'Range': 'bytes=0-4' } try: r = requests.head(url, headers = headers) crange = r.headers['content-range'] self.total = int(re.match(ur'^bytes 0-4/(\d+)$', crange).group(1)) return True except: pass try: self.total = int(r.headers['content-length']) except: self.total = 0 return False 用正则匹配出大小,获得直接获取headers['content-length'],获得将其设置为0.
核心代码基本上就是这些,再就是一些设置了,各位更可以去github直接看:
运行来获取一下emlog最新的安装包:
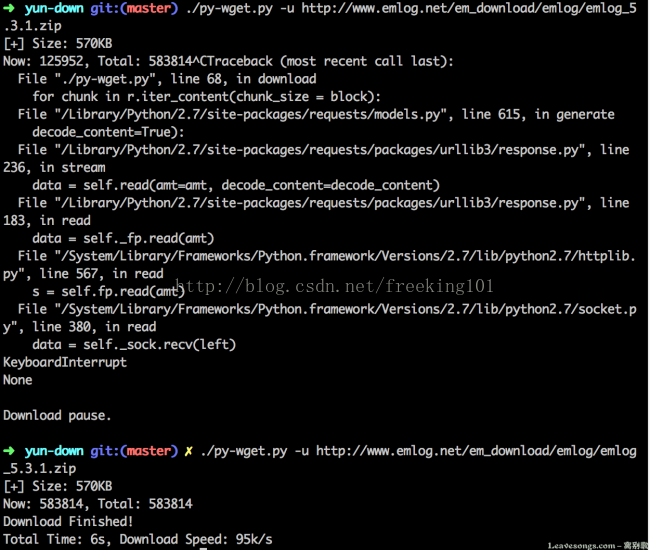
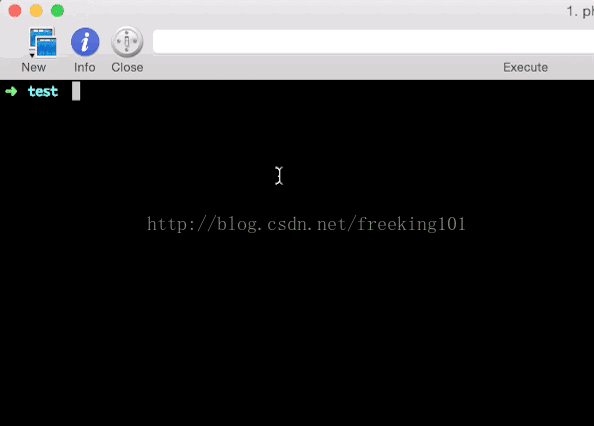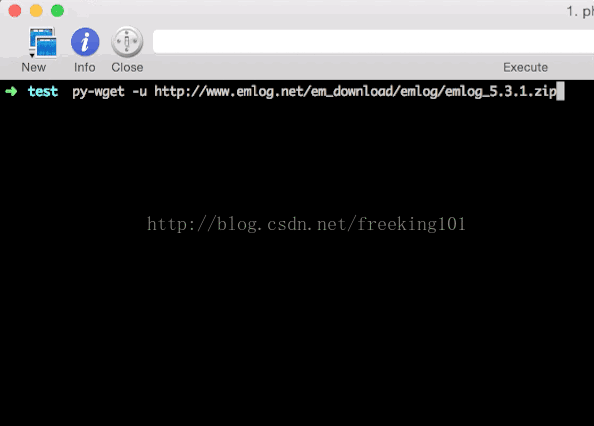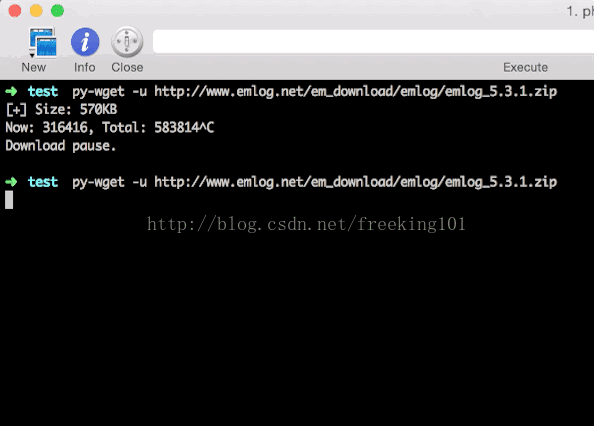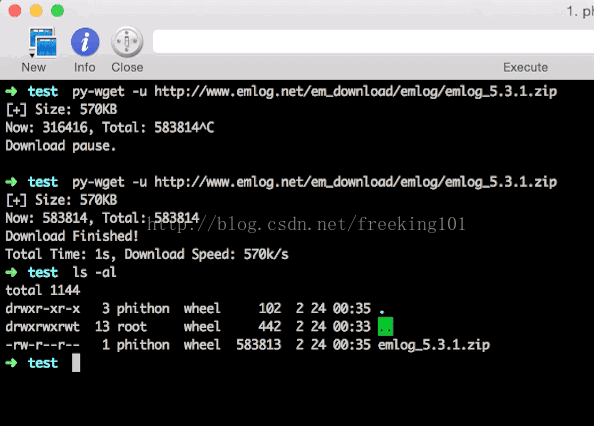
中间我按Contrl + C人工打断了下载进程,但之后还是继续下载,实现了“断点续传”。但在我实际测试过程中,并不是那么多请求可以断点续传的,所以我对于不支持断点续传的文件这样处理:重新下载。
下载后的压缩包正常解压,也充分证明了下载的完整性:
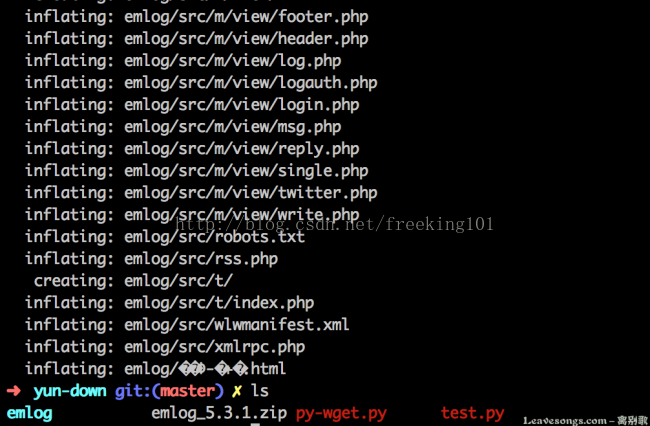
动态图演示
如果你想把我的这个小脚本当一个工具来用的话,可以查看github下的说明:
多线程下载文件
# 在python3下测试 import sysimport requestsimport threadingimport datetime # 传入的命令行参数,要下载文件的urlurl = sys.argv[1] def Handler(start, end, url, filename): headers = {'Range': 'bytes=%d-%d' % (start, end)} r = requests.get(url, headers=headers, stream=True) # 写入文件对应位置 with open(filename, "r+b") as fp: fp.seek(start) var = fp.tell() fp.write(r.content) def download_file(url, num_thread = 5): r = requests.head(url) try: file_name = url.split('/')[-1] file_size = int(r.headers['content-length']) # Content-Length获得文件主体的大小,当http服务器使用Connection:keep-alive时,不支持Content-Length except: print("检查URL,或不支持对线程下载") return # 创建一个和要下载文件一样大小的文件 fp = open(file_name, "wb") fp.truncate(file_size) fp.close() # 启动多线程写文件 part = file_size // num_thread # 如果不能整除,最后一块应该多几个字节 for i in range(num_thread): start = part * i if i == num_thread - 1: # 最后一块 end = file_size else: end = start + part t = threading.Thread(target=Handler, kwargs={'start': start, 'end': end, 'url': url, 'filename': file_name}) t.setDaemon(True) t.start() # 等待所有线程下载完成 main_thread = threading.current_thread() for t in threading.enumerate(): if t is main_thread: continue t.join() print('%s 下载完成' % file_name) if __name__ == '__main__': start = datetime.datetime.now().replace(microsecond=0) download_file(url) end = datetime.datetime.now().replace(microsecond=0) print("用时: ", end='') print(end-start) Python下载图片、音乐、视频
# -*- coding:utf-8 -*-import reimport requestsfrom contextlib import closingfrom lxml import etreeclass Spider(object): """ crawl image """ def __init__(self): self.index = 0 self.url = "http://www.xiaohuar.com" self.proxies = {"http": "http://172.17.18.80:8080", "https": "https://172.17.18.80:8080"} pass def download_image(self, image_url): real_url = self.url + image_url print "downloading the {0} image".format(self.index) with open("{0}.jpg".format(self.index), 'wb') as f: self.index += 1 f.write(requests.get(real_url, proxies=self.proxies).content) pass pass def start_crawl(self): start_url = "http://www.xiaohuar.com/hua/" r = requests.get(start_url, proxies=self.proxies) if r.status_code == 200: temp = r.content.decode("gbk") html = etree.HTML(temp) links = html.xpath('//div[@class="item_t"]//img/@src') map(self.download_image, links) # next_page_url = html.xpath('//div[@class="page_num"]//a/text()') # print next_page_url[-1] # print next_page_url[-2] # print next_page_url[-3] next_page_url = html.xpath(u'//div[@class="page_num"]//a[contains(text(),"下一页")]/@href') page_num = 2 while next_page_url: print "download {0} page images".format(page_num) r_next = requests.get(next_page_url[0], proxies=self.proxies) if r_next.status_code == 200: html = etree.HTML(r_next.content.decode("gbk")) links = html.xpath('//div[@class="item_t"]//img/@src') map(self.download_image, links) try: next_page_url = html.xpath(u'//div[@class="page_num"]//a[contains(text(),"下一页")]/@href') except BaseException as e: next_page_url = None print e page_num += 1 pass else: print "response status code : {0}".format(r_next.status_code) pass else: print "response status code : {0}".format(r.status_code) passclass ProgressBar(object): def __init__(self, title, count=0.0, run_status=None, fin_status=None, total=100.0, unit='', sep='/', chunk_size=1.0): super(ProgressBar, self).__init__() self.info = "[%s] %s %.2f %s %s %.2f %s" self.title = title self.total = total self.count = count self.chunk_size = chunk_size self.status = run_status or "" self.fin_status = fin_status or " " * len(self.status) self.unit = unit self.seq = sep def __get_info(self): # 【名称】状态 进度 单位 分割线 总数 单位 _info = self.info % (self.title, self.status, self.count / self.chunk_size, self.unit, self.seq, self.total / self.chunk_size, self.unit) return _info def refresh(self, count=1, status=None): self.count += count # if status is not None: self.status = status or self.status end_str = "\r" if self.count >= self.total: end_str = '\n' self.status = status or self.fin_status print self.__get_info(), end_strdef download_mp4(video_url): print video_url try: with closing(requests.get(video_url.strip().decode(), stream=True)) as response: chunk_size = 1024 with open('./{0}'.format(video_url.split('/')[-1]), "wb") as f: for data in response.iter_content(chunk_size=chunk_size): f.write(data) f.flush() except BaseException as e: print e returndef mp4(): proxies = {"http": "http://172.17.18.80:8080", "https": "https://172.17.18.80:8080"} url = "http://www.budejie.com/video/" r = requests.get(url) print r.url if r.status_code == 200: print "status_code:{0}".format(r.status_code) content = r.content video_urls_compile = re.compile("http://.*?\.mp4") video_urls = re.findall(video_urls_compile, content) print len(video_urls) # print video_urls map(download_mp4, video_urls) else: print "status_code:{0}".format(r.status_code)def mp3(): proxies = {"http": "http://172.17.18.80:8080", "https": "https://172.17.18.80:8080"} with closing(requests.get("http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3", proxies=proxies, stream=True)) as response: chunk_size = 1024 content_size = int(response.headers['content-length']) progress = ProgressBar("razorback", total=content_size, unit="KB", chunk_size=chunk_size, run_status="正在下载", fin_status="下载完成") # chunk_size = chunk_size < content_size and chunk_size or content_size with open('./file.mp3', "wb") as f: for data in response.iter_content(chunk_size=chunk_size): f.write(data) progress.refresh(count=len(data))if __name__ == "__main__": t = Spider() t.start_crawl() mp3() mp4() pass 下载视频的效果